|
I am a Senior Research Scientist at Databricks working as a technical lead for RL training for agentic systems. I was previously a Ph.D. student in the Computer Science department at Cornell University, advised by Wen Sun. Before Cornell, I recieved my bachelors in Computer Science and Applied Mathematics from Brown University in 2018, working with Stefanie Tellex and George Konidaris in the Humans to Robots (H2R) Laboratory. CV / Email / Google Scholar / Github / LinkedIn |

|
|
I am interested in machine learning, specifically imitation learning and reinforcement learning, and its intersection with generative models. I am particularly interested in studying how to leverage expert demonstrations and learned feature representations for scalable, efficient reinforcement learning. Recently, I have been invested in investigating imitation learning and reinforcement learning for Large Language Models, improving sample efficiency, reducing reward hacking, and developing improved RLHF algorithms. |
|
Jonathan D. Chang, Andrew Drozdov, Shubham Toshniwal, Owen Oertell, Alexander Trott, Jacob Portes, Abhay Gupta, Pallavi Koppol, Ashutosh Baheti, Sean Kulinski, Ivan Zhou, Irene Dea, Krista Opsahl-Ong, Simon Favreau-Lessard, Sean Owen, Jose Javier Gonzalez Ortiz, Arnav Singhvi, Xabi Andrade, Cindy Wang, Kartik Sreenivasan, Sam Havens, Jialu Liu, Peyton DeNiro, Wen Sun, Michael Bendersky, Jonathan Frankle arXiv:2603.05218, 2026 arXiv |
|
|
Daniel Ritter, Owen Oertell, Bradley Guo, Jonathan D. Chang, Kianté Brantley, Wen Sun arXiv:2602.19362, 2026 arXiv |
|
|
Alnur Ali, Ashutosh Baheti, Jonathan D. Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Krista Opsahl-Ong, Jose Javier Gonzalez Ortiz, Matei Zaharia, Yue Zhang arXiv:2509.21459, 2025 arXiv |
|
|
Yiran Jenny Shen, Yu Xia, Jonathan D. Chang, Prithviraj Ammanabrolu Preprint, 2025 |
|
|
Jin Peng Zhou, Kaiwen Wang, Jonathan D. Chang, Zhaolin Gao, Nathan Kallus, Kilian Q. Weinberger, Kianté Brantley, Wen Sun NeurIPS, 2025 |
|
|
Kaiwen Wang*, Jin Peng Zhou*, Jonathan D. Chang*, Zhaolin Gao, Nathan Kallus, Kianté Brantley, Wen Sun NeurIPS, 2025 |
|
|
Zhaolin Gao, Wenhao Zhan, Jonathan D. Chang, Gokul Swamy, Kianté Brantley, Jason D. Lee, Wen Sun ICLR, 2025 |
|
|
Zhaolin Gao*, Jonathan D. Chang*, Wenhao Zhan, Owen Oertell, Gokul Swamy, Kianté Brantley, Thorsten Joachims, J. Andrew Bagnell, Jason D. Lee, Wen Sun NeurIPS, 2024 |
|
|
Owen Oertell, Jonathan D. Chang, Yiyi Zhang, Kianté Brantley, Wen Sun Reinforcement Learning Conference (RLC), 2024 |
|
|
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D. Chang, Prithviraj Ammanabrolu arXiv:2408.11791, 2024 arXiv |
|
|
Jonathan D. Chang*, Wenhao Zhan*, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun arXiv:2404.08495, 2024 arXiv |
|
|
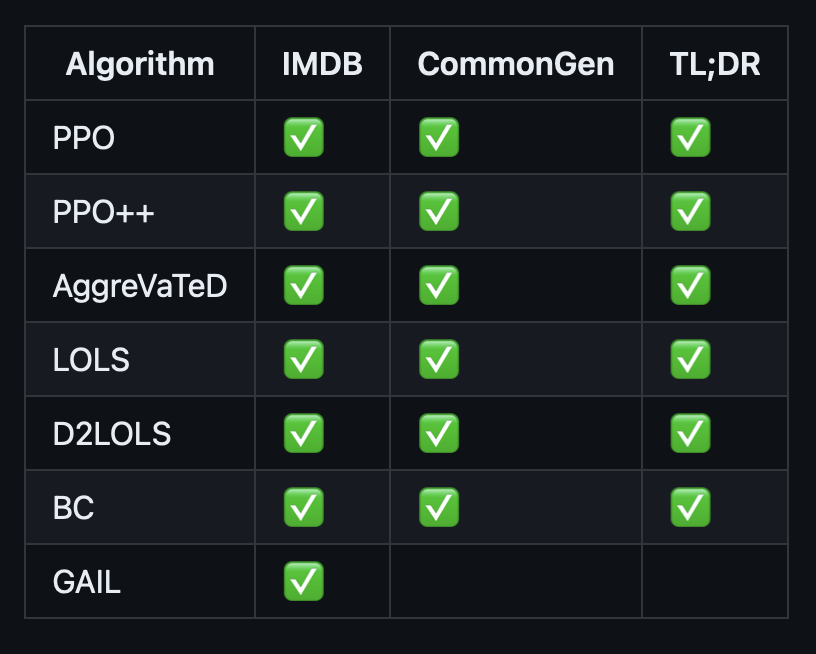
Jonathan D. Chang*, Kianté Brantley*, Rajkumar Ramamurthy, Dipendra Misra, Wen Sun Repository, 2024 Github Developed, distributed research codebase for RL and IL algorithm development with large LLMs. Deepspeed, transformers, PEFT, and FSDP integration. |
|
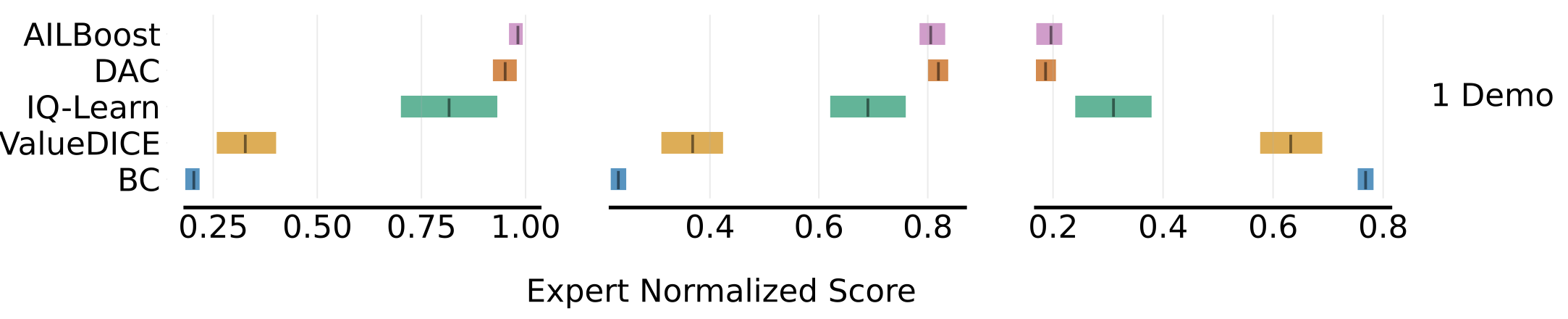
Jonathan D. Chang, Dhruv Sreenivas*, Yingbing Huang*, Kianté Brantley, Wen Sun ICLR, 2024 OpenReview |
|
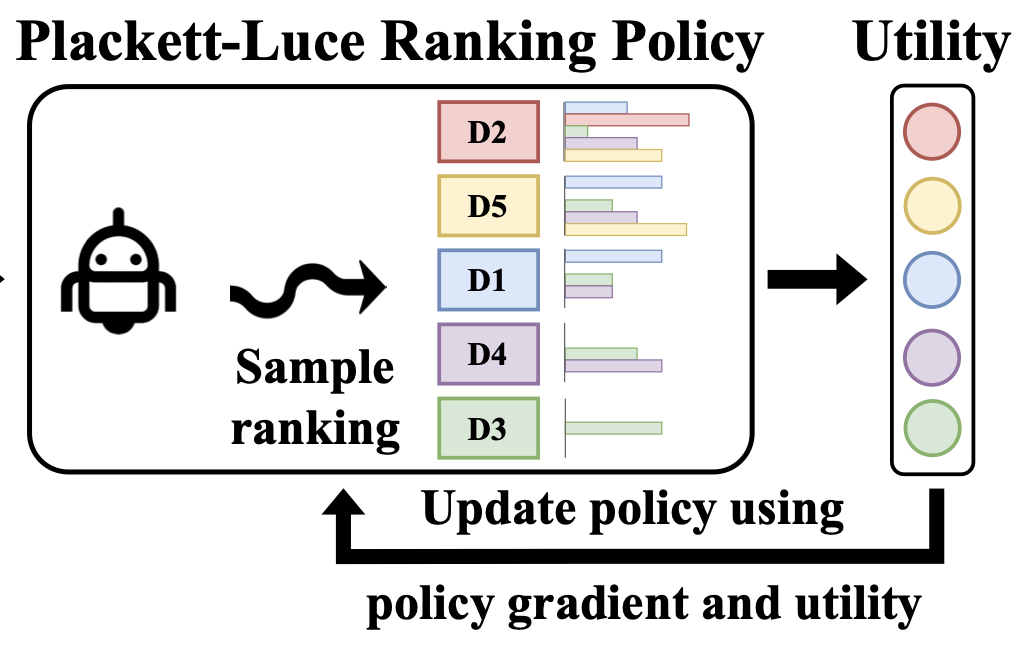
Ge Gao, Jonathan D. Chang, Kianté Brantley, Claire Cardie, Thorsten Joachims FMDM@NeurIPS, 2023 arXiv |
|
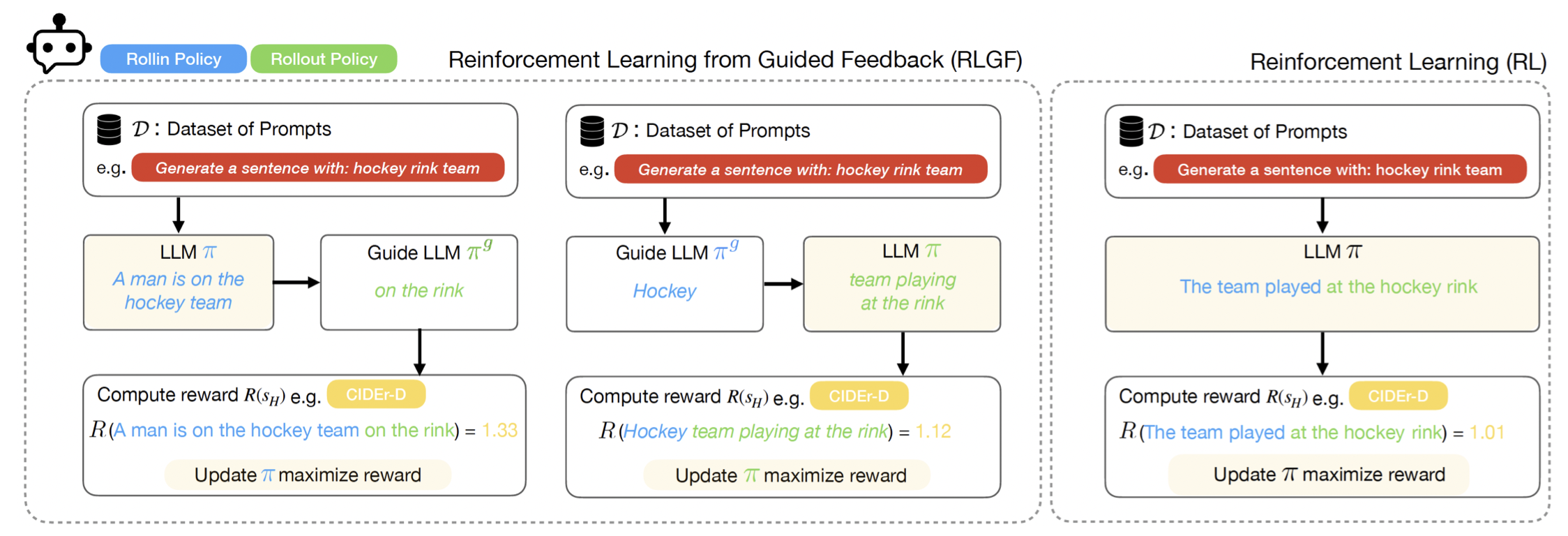
Jonathan D. Chang*, Kianté Brantley*, Rajkumar Ramamurthy, Dipendra Misra, Wen Sun arXiv:2306.11816, 2023 arXiv |
|
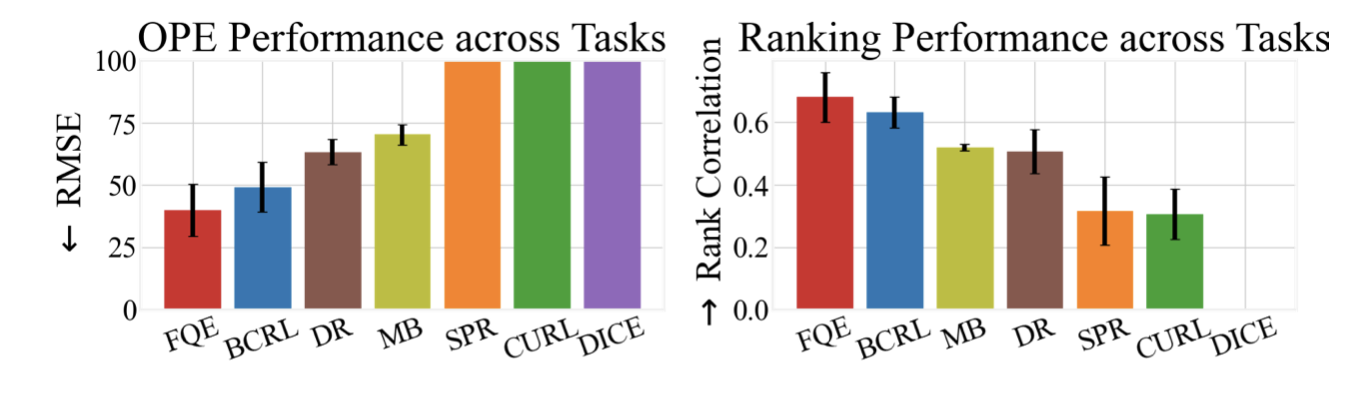
Jonathan D. Chang*, Kaiwen Wang*, Nathan Kallus, Wen Sun ICML 2022 (Long Talk), 2022 code / arXiv Representation learning for Offline Policy Evaluation (OPE) guided by Bellman Completeness and coverage. BCRL achieves state-of-the-art evaluation on image based, continuous control tasks from Deepmind Control Suite. |
|
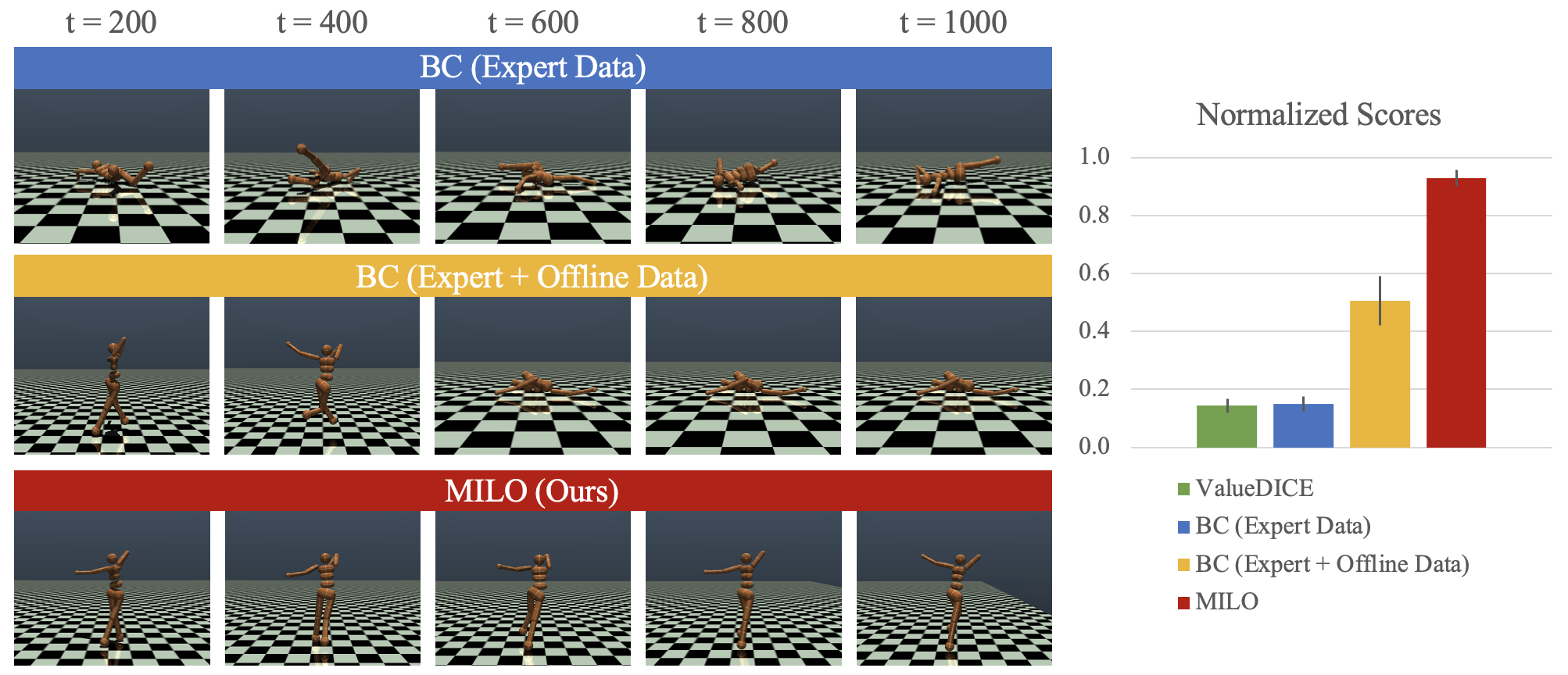
Jonathan D. Chang*, Masatoshi Uehara*, Dhruv Sreenivas, Rahul Kidambi, Wen Sun NeurIPS 2021, 2021 code / arXiv Leveraging offline data with only partial coverage, MILO mitigates covariate shift in imitation learning. |
|
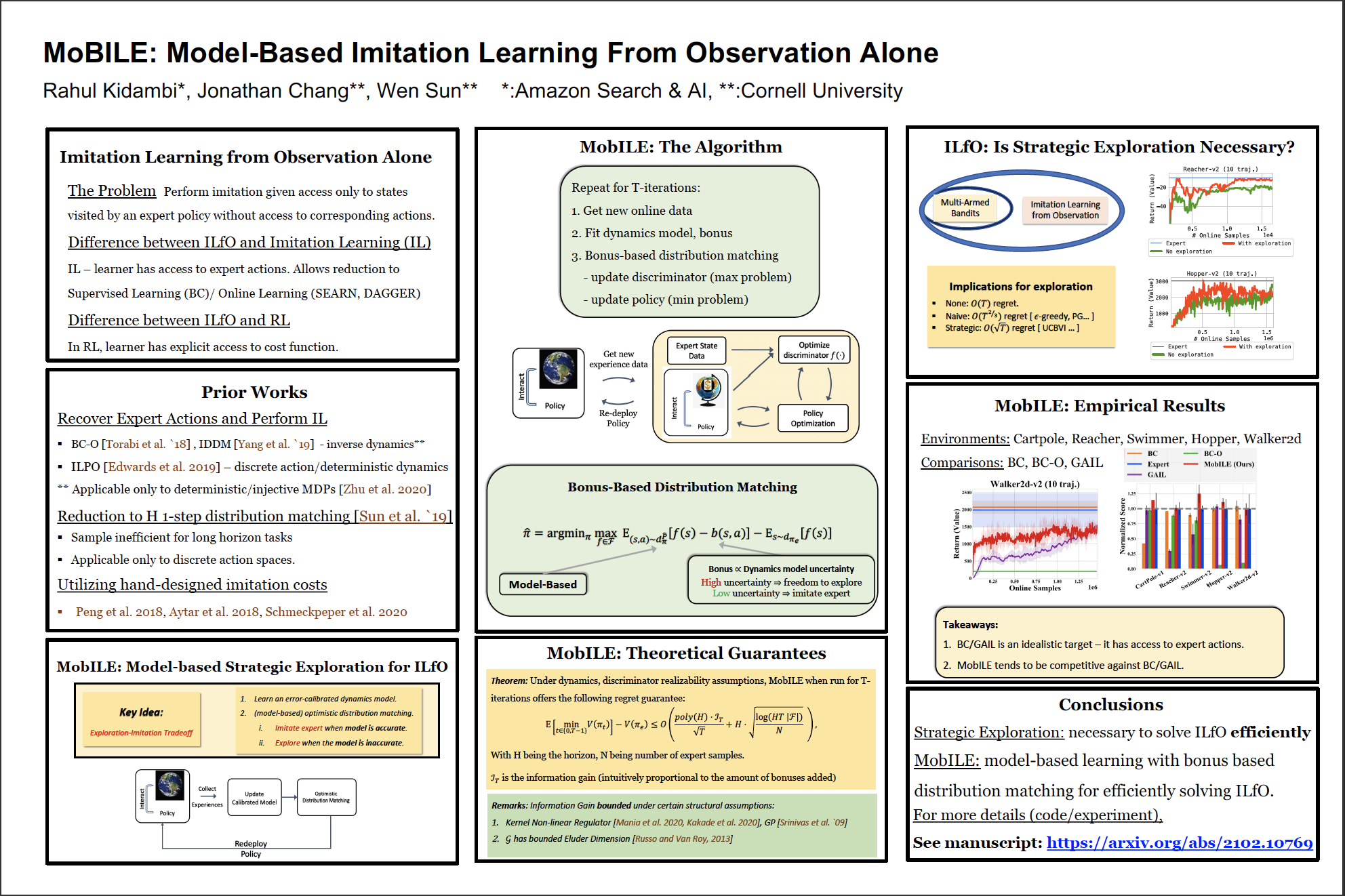
Rahul Kidambi, Jonathan D. Chang, Wen Sun NeurIPS 2021, 2021 arXiv We show that model-based imitation learning from observations (IfO) with strategic exploration can near-optimally solve IfO both in theory and in practice. |
|
|
|
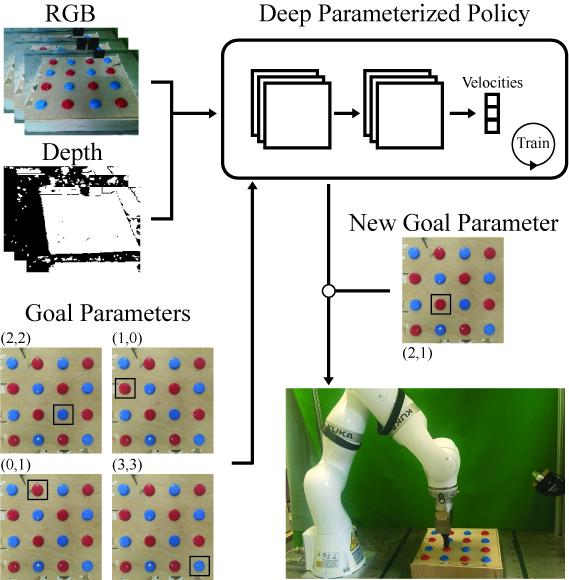
Jonathan D. Chang*, Nishanth Kumar, Sean Hastings, Aaron Gokaslan, Diego Romeres, Devesh Jha, Daniel Nikovski, George Konidaris, Stefanie Tellex arXiv We introduce an end-to-end method for targetable visuomotor skills as a goal-parameterized neual network policy, resulting in successfully learning a mapping from target pixel coordinates to a robot policy. |
|
|
|
Reviewer: NeurIPS 2021, ICML 2022, ICLR 2022, NeurIPS 2022, NeurIPS 2023, ICML 2023, ICLR 2024, NeurIPS 2024, ICML 2024 |
|
Website template is from Jon Barron's website. |